L'arca olearia
Il panel test per l'olio d'oliva va aiutato a migliorarsi grazie all'analisi chimica
Oltre alle molecole della via della lipossigenasi, troviamo l’E,E-hexa-2,4-dienal e l’isobutanol, molecole ad oggi mai associate alle note positive degli oli. Dall'Università di Firenze un approccio chimico/statistico basato sull’analisi della frazione volatile di 1200 campioni
25 ottobre 2019 | Lorenzo Cecchi, Nadia Mulinacci
 Gli oli vergini d’oliva si ottengono dal frutto d’olivo (Olea europaea L.) solo mediante mezzi fisici o meccanici in condizioni da non portare ad alterazioni degli oli, e sono caratterizzati da sensazioni olfattive positive verdi e fruttate o, talvolta, da note sensoriali sgradevoli. Le prime sono dovute a composti volatili a 5 o 6 atomi di carbonio che si formano a partire dagli acidi grassi attraverso la via della lipossigenasi (LOX-pathway) durante le fasi di frangitura e gramolazione; le seconde sono dovute principalmente a processi ossidativi o microbiologici (come fermentazioni aerobiche o anaerobiche).
Gli oli vergini d’oliva si ottengono dal frutto d’olivo (Olea europaea L.) solo mediante mezzi fisici o meccanici in condizioni da non portare ad alterazioni degli oli, e sono caratterizzati da sensazioni olfattive positive verdi e fruttate o, talvolta, da note sensoriali sgradevoli. Le prime sono dovute a composti volatili a 5 o 6 atomi di carbonio che si formano a partire dagli acidi grassi attraverso la via della lipossigenasi (LOX-pathway) durante le fasi di frangitura e gramolazione; le seconde sono dovute principalmente a processi ossidativi o microbiologici (come fermentazioni aerobiche o anaerobiche).
In base alla legislazione vigente, gli oli vergini di oliva possono essere classificati come Olio extravergine di oliva (EVOO), Olio Vergine di Oliva (VOO) e Olio Vergine Lampante di Oliva (LVOO), in funzione delle loro caratteristiche chimiche e sensoriali. Il valore commerciale di queste diverse categorie è molto diverso, pertanto una corretta classificazione assume un’importanza fondamentale per la tutela sia del consumatore, che deve vedere garantita la corrispondenza del prodotto che acquista con quello che viene dichiarato in etichetta, sia del produttore.
Il metodo ufficiale per la valutazione dei difetti degli oli è il Panel Test, metodologia che soffre di soggettività e dell’emozionalità degli assaggiatori, talvolta di scarsa riproducibilità di valutazione del solito campione da parte di diversi panel e di alti costi. È un metodo spesso anche lento, a causa della fatica sensoriale dopo l’assaggio di un alto numero di campioni. Per questo, è da tempo sentita la necessità di un approccio chimico/statistico (chemometrico), robusto e affidabile, per supportare il panel test nella classificazione degli oli di oliva. A tal fine, come primo passo verso il raggiungimento di questo obbiettivo, tre anni fa l’università di Firenze ha messo a punto un metodo chimico per l’analisi dei composti volatili
basato sulla microestrazione in fase solida dello spazio di testa seguita da analisi in cromatografia accoppiata al rivelatore di massa (HS-SPME-GC-MS) [1]. Il metodo permette la quantificazione di 73 composti volatili in una ampio range di concentrazioni, tali da permettere di coprire la variabilità nella quasi totalità degli oli presenti sul mercato, di diversa qualità e provenienza (https://www.teatronaturale.it/strettamente-tecnico/l-arca-olearia/23961-l-analisi-chimica-in-supporto-al-panel-test-un-nuovo-approccio-e-un-nuovo-metodo.htm).
A partire da tale metodo, nell’ambito del progetto FOODOLEAPLUS finanziato dalla Regione Toscana, grazie ad una collaborazione fra il Dipartimento di NEUROFARBA dell’Università di Firenze e la Carapelli Firenze S.p.A., è stato sviluppato un approccio che permette di supportare il panel test nella classificazione degli oli vergini di oliva,. A tal fine, sono stati collezionati 1223 oli vergini di oliva commerciali durante tre campagne olearie (2016/2017, 2017/2018 e 2018/2019) e da diverse origini (Spagna 34,5%, Italia 26,7%, Grecia 23,6%, Portogallo 6,9%, Tunisia 6,7%, altro 1.6%). I campioni, dopo le analisi chimiche e sensoriali sono risultati: 5 lampanti (che sono stati considerati outlier ed esclusi dalla successiva trattazione statistica), 562 extra vergini e 656 vergini. La maggior parte dei campioni aveva una mediana del difetto inferiore a 1.5, e sono stati considerati difficili da classificare dal panel test; questo fatto, unito all’alto numero di campioni, ha creato un set di campioni che, sia dal punto di vista qualitativo che da quello quantitativo, era quello più adatto per sviluppare un modello robusto per la classificazione merceologica degli oli d’oliva.
Per la creazione del modello, tutti i 1218 campioni sono stati sottoposti all’analisi dei composti volatili e all’analisi sensoriale.
In base all’analisi sensoriale sono stati suddivisi in Extravergini (EV) e difettati (DE). Quelli difettati sono stati ulteriormente classificati in difettati per difetti ossidativi (OX) o microbiologici (MI). A partire da questo set di dati sono stati sviluppati 4 modelli chemometrici per la classificazione degli oli.
Il primo modello si basa su due strumenti statistici: l’analisi delle componenti principali (PCA) e l’analisi discriminante lineare (LDA). Il modello è stato costruito utilizzando un training set di circa 1000 campioni e validato internamente in 10 cicli, usando alternativamente tutti i campioni. Il modello era in grado di classificare l’82.1% dei campioni in accordo al panel test.
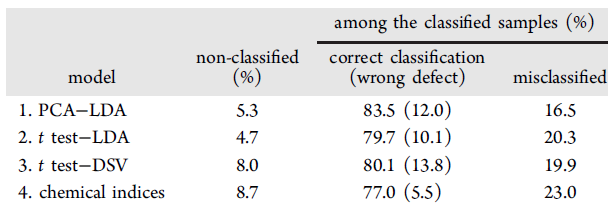
Il modello è stato poi successivamente validato esternamente usando un set di circa 300 campioni indipendenti. La tabella 1 mostra i risultati ottenuti durante la validazione esterna di tutti i 4 modelli proposti: come si vede il modello PCA-LDA ha permesso di classificare correttamente (in accordo al panel test) l’83.5% dei campioni.
I successivi tre modelli sono stati costruiti con gli obbiettivi di i) ridurre il numero di composti volatili necessari, in maniera da ridurre costi e tempi di analisi e ii) avere informazioni qualitative sulle molecole più in grado di discriminar fra le diverse categorie di olio.
I dati in tabella 1 relativi agli approcci 2, 3 e 4 mostrano che la percentuale di campioni classificati correttamente è solo leggermente inferiore rispetto all’approccio sopra descritto. In particolare, l’approccio 3, basato sul t-test per la selezione delle molecole più in grado di discriminare fra le varie categorie merceologiche di olio e sulla definizione di valori discriminanti, ha permesso di ottenere una classificazione corretta dell’80,1% dei campioni, usando solo 10 composti volatili: 5 per discriminare fra campioni extravergini e difettati, 5 per discriminare fra campioni difettati per difetti di origine ossidativa o microbiologica.
Per valutare i dati ottenuti, si deve sempre tenere conto che il panel test non fornisce sempre una classificazione affidabile dei campioni, pertanto i campioni non ben classificati dai modelli possono essere non ben classificati dal panel test o dal modello; inoltre, il set di campioni era costituito da quelli più difficili da classificare da parte del panel test. Alla luce di queste considerazioni, l’83,5% di classificazione corretta ottenuta con il modello PCA-LDA è un risultato molto soddisfacente, che permette di proporre questo modello come metodo ufficiale nei laboratori per analisi di routine.
Per quanto riguarda i volatili maggiormente responsabili della classificazione dei campioni, le maggiori informazioni qualitative si sono ottenute con il quarto approccio, basato sulla definizione di indici chimici dati dalla somma dei volatili maggiormente capaci di discriminare ogni categoria di oli e ogni categoria di difetti. La tabella 2 riassume i risultati ottenuti, in cui le sigle indicano: EV, extravergine; Mi-Fu, oli difettati per difetto di riscando; Mi-Wi, oli difettati per difetto di avvinato; Mi-Mu, oli difettati per difetto di muffa; Ox, oli difettati per difetti ossidativi.
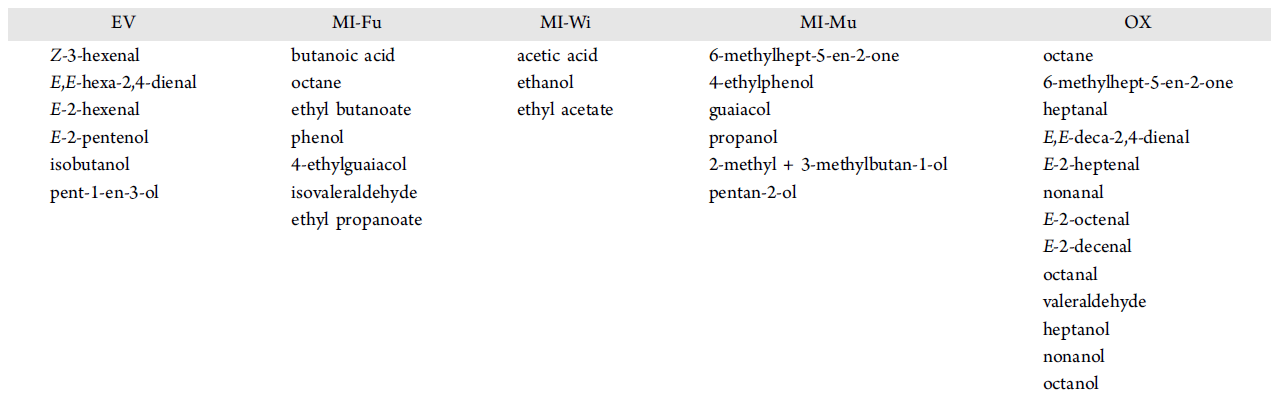
In breve, per quanto riguarda gli oli extravergini, oltre alle molecole della via della lipossigenasi, troviamo l’E,E-hexa-2,4-dienal e l’isobutanol, molecole ad oggi mai associate alle note positive degli oli. Per quanto riguarda i difetti ossidativi, oltre alle molecole già associate a questo tipo di difetti, troviamo alcoli quali heptan-1-ol ed octan-1-ol. Per quanto riguarda i difetti microbiologici, le maggiori differenze riguardano il difetto di muffa, per il quale i volatili proposti sono diversi dai tipici alcoli e chetoni ad 8 atomi di carbonio tipicamente riportati in bibliografia. Infine, considerando tutti i modelli proposti, 5 molecole sono sempre in grado di differenziare i campioni extravergini da quelli difettati: octane, heptanal, pent-1-en-3-ol, Z-3-hexenal, nonanal and 4-ethylphenol. Queste molecole possono essere considerate come un gruppo di composti volatili di base per discriminare campioni extravergini da quelli difettati.
Concludendo, i 4 modelli proposti hanno dato risultati non molto diversi l’uno dall’altro, confermando la robustezza degli approcci basati sui dati ottenuti dall’analisi dei composti volatili. L’approccio PCA-LDA è proposto come quello più efficace per supportare il panel test nella classificazione degli oli vergini di oliva; il terzo modello (t-test/DSV) è un’utile alternativa per semplificare il lavoro analitico riducendo fortemente il numero di molecole da quantificare, mentre il quarto modello (basato sugli indici chimici) può essere applicato quando si vuole discriminare i campioni difettati anche in funzione del difetto.
Bibliografia
1. Fortini, Migliorini, Cherubini, Cecchi, Calamai. Multiple internal standard normalization for improving HS-SPME-GC-MS quantitation in virgin olive oil volatile organic compounds (VOO-VOCs) profile. Talanta. 2017, 165, 641-652.
2. Cecchi, Migliorini, Giambanelli, Rossetti, Cane, Melani, Mulinaci. Headspace Solid-Phase Microextraction−Gas Chromatography−Mass Spectrometry Quantification of the Volatile Profile of More than 1200 Virgin Olive Oils for Supporting the Panel Test in Their Classification: Comparison of Different Chemometric Approaches. Journal of Agricultural and Food Chemistry, 2019. 67, 9112-9120. DOI: 10.1016/j.jff.2017.12.018.
Potrebbero interessarti
L'arca olearia
L'effetto mascheramento dei fenoli sulla percezione sensoriale dell'olio extravergine di oliva

I composti fenolici, responsabili dell'amaro e del piccante, possano influenzare la percezione degli attributi positivi e negativi durante l'assaggio. Dimostrato che un'alta concentrazione di polifenoli riduce la percezione del fruttato del 39%, maschera il difetto di riscaldo ma esalta l'avvinato
02 luglio 2026 | 16:00
L'arca olearia
Biostimolanti microbici sull'olivo: crescita, metabolismo e resilienza climatica

Un recente studio italiano svela come i consorzi microbici possano migliorare la crescita dell'olivo agendo in profondità sul metabolismo del carbonio e dell'azoto. Ecco cosa cambia per gli olivicoltori
02 luglio 2026 | 12:00
L'arca olearia
L'effetto della pacciamatura sulla qualità dell'olio d'oliva in condizioni di siccità

Valutata l'efficacia di diverse tecniche di pacciamatura nel preservare la qualità dell'olio di oliva, su olivo sottoposto a tre diversi regimi idrici. La pacciamatura con sansa di oliva e letame animale offre i migliori risultati
01 luglio 2026 | 15:00
L'arca olearia
Usura e corrosione del frantoio causati dalle olive e dalla pasta di olive

Ecco i meccanismi di degrado che colpiscono i componenti in acciaio inossidabile AISI 304L impiegati in frangitori a martelli e centrifughe orizzontali per la separazione dei noccioli. I fenomeni di tribocorrosione, l'usura abrasiva e l'incrudimento superficiale che portano al fallimento dei componenti dopo appena tre settimane di servizio
01 luglio 2026 | 13:00
L'arca olearia
I fitoprostani come biomarcatori di ossidazione: la relazione tra stress idrico e qualità dell'olio d'oliva

L'irrigazione deficitaria controllata durante l'indurimento del nocciolo dell'oliva, tradizionalmente considerato un periodo fenologico non critico, si rivela invece un fattore chiave che influenza positivamente il profilo bioattivo dell'olio extra vergine di oliva
01 luglio 2026 | 11:00
L'arca olearia
I formulati a basso contenuto di rame che possono combattere l'occhio di pavone dell'olivo

Dimostra l'efficacia di formulazioni innovative a ridotto contenuto di rame contro l'agente dell'occhio di pavone dell'olivo, la Venturia oleaginea, aprendo scenari inediti per la protezione sostenibile dell'olivicoltura mediterranea
30 giugno 2026 | 13:00